

REDMI Note 17 Pro评测:同档最强抗摔防水,2026年千元机市场的品质守门员
2026-07-14
近几年,视频行业迎来了井喷式爆发,随着人工智能技术的逐渐成熟,用户体验不断升级。
在观看影视剧、综艺等视频时,我们总能在画面中看到跟视频场景相关的广告,比如当出现地标性建筑时,会出现旅游相关广告;当观看明星真人秀节目,会有同款服饰的购物链接。在这背后,是智能视频识别技术发展的成果。
近期,极链科技AI研究院资深研究员张奕在智东西公开课上进行了主题为《消费级视频内容识别的算法设计与应用》的讲解,从视联网产业简介、智能视频技术应用于消费级视频的挑战、数据的重要性与VideoNet视频数据集、视频内容识别的算法设计与应用四大模块进行了分享。
以下为分享实录:
在5G和AI的加持下,互联网演进出三大形态,物联网,视联网和车联网。目前视频占据了全网数据的80%,且仍在不断提高。视频将成为互联网最重要的入口,承担起信息传递介质和互联网功能载体的作用,进而形成以视频作为主要信息传递介质和功能载体的互联网形态,视联网。庞大的消费级视频是视联网的首个落地场景。
作为「AI+视频」行业独角兽企业,全球视联网开源操作系统构建者,极链科技专注于消费级视频AI技术研发和商业应用,聚焦以视频作为信息和功能核心载体的新互联网形态——视联网。以AI技术赋能视频中的信息,链接互联网信息、服务、购物、社交、游戏五大模式,实现基于视频的新互联网经济体。极链科技自主研发的VideoAI是视联网整个生态的底层引擎,VideoOS为视联网底层操作系统,是继PC时代Linux系统和移动互联网时代安卓系统之后的第三大操作系统。以VideoAI、VideoOS为基础,开发出广告、电商等各类视联网应用。
视联网的基础数据即视频,尤其是消费级视频。区别于工业级视频是利用专业设备在固定条件、固定场景下拍摄的视频,如监控视频。消费级视频是指用户用手机等便携式图像采集设备生成的视频。消费级视频有三大特点。一,消费级视频数据体量巨大;二,消费级视频的类别多样,如电影、综艺、体育、短视频等;三,消费级视频场景复杂,如场景内的特效、切换、淡入淡出和字幕,都会对整体或局部产生模糊。以上特点对视频识别算法提出了更高的挑战。
视频识别算法本身有较长的历史,然而受到计算能力的限制,算法各项性能与产品商业化要求间还存在较大的差距。直到2012年,深度学习技术、大数据及GPU算力的结合极大提升了算法准确率和运算效率,拉低了与产品商业化要求的差距。
众所周知,深度学习的成功建立在大规模数据集的基础上。现有视频数据集从规模、维度和标注方式上都与深度学习算法的要求存在很大差距。今年,极链科技与复旦大学联合推出了全新的VideoNet视频数据集,具备规模大、多维度标注、标注细三大特点。

第一,规模大。VideoNet数据集包含逾9万段视频,总时长达4000余小时。
第二,多维度标注。视频中存在着大量的物体、场景等多维度内容信息,这些维度内容之间又存在着广泛的语义联系。近年来涌现出大量针对物体、场景、人脸等维度的识别技术,在各自的目标维度上取得了明显的进步。但各视频识别算法基本针对单一维度来设计的,无法利用各维度之间存在的丰富的语义关联建立模型,提高识别准确度。VideoNet数据集从事件、物体、场景三个维度进行了联合标注,为多维度视频识别算法研提供支持。
第三,标注细。视频标注工作量非常巨大,当前大部分视频仅针对整段视频打标签。而VideoNet数据集对视频进行了事件分类标注,并针对每个镜头的关键帧进行了场景和物体两个维度的共同标注,充分体现了多维度内容之间的语义联系。
那么,VideoNet数据集是如何进行标注的?首先,对视频数据进行预处理,即镜头分割,并根据清晰度对镜头单元进行关键帧提取。之后从三个维度进行视频标注,事件维度上对整个视频标注类别标签,物体维度上对镜头关键帧标注类别和位置框,场景维度上对镜头关键帧标注类别标签。目前,VideoNet数据集包含353类事件,超过200类场景和200类物体,总视频数达到9万。其中60%作为训练集,20%作为验证集,20%作为测试集。
自6月18日「VideoNet视频内容识别挑战赛」公布训练和验证数据集以来,截止到8月12日,注册报名的队伍已超过360支,其中参赛队伍当中有来自中科院、北京大学、中国科学技术大学等顶尖高校队伍以及来自阿里巴巴、京东、华为、腾讯、大华等众多知名企业队伍。预计明年,极链科技将会继续增加VideoNet数据集的规模和标注维度。

消费级视频的数据特点,对算法系统的处理速度、效率和准确率提出了较高的要求。消费级视频算法的总体框架分为五层:1、视频输入层进行视频源的管理;2、视频处理层进行镜头分割、采样、增强和去噪等工作;3、内容提取层主要分析视频中内容、语义等信息,进行目标检测、跟踪和识别等来检测目标在视频中的时间、空间、位置等维度;4、语义融合层进行目标轨迹融合、识别结果融合、特征表示融合、高层语义融合等;5、在数据输出层,进行结构化数据管理,方便后续数据检索与应用。
视频内容识别维度多样,包括场景、物体、人脸、地标、Logo、情绪、动作、声音等。不同维度的算法结构有所区别。人脸识别算法结构为:输入视频后进行镜头分割,在进行人脸检测、跟踪、人脸对齐,根据质量评估过滤,进行特征提取和特征比对识别,最后进行识别结果融合,输入最终识别结果。
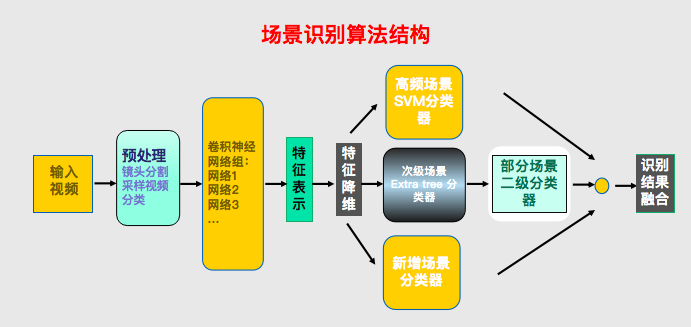
在场景识别算法结构中,首先对输入视频进行镜头分割采样,有所不同的是只需进行时间间隔分割的采样,再对视频进行场景类别的初分类,预处理之后进入卷积神经网合阶段,卷积神经网络通过对不同的数据集进行预训练,得到不同的特征和描述,将这些特征进行融合、降维处理得到特征表示后,对不同场景如高频场景、次级场景和新增场景,进行分类处理,最终对识别结果进行融合。
在物体、Logo识别算法结构中,有所不同的是需要多尺度提取特征,跟踪识别物体轨迹,并关注物体类别,对结果进行优化。
在地标识别算法结构中,分为三步,第一,通过基础网络(VGG,ResNet等)获得特征图(一般为最后一层卷积或池化层);第二,从特征图中提取特征(例如R-Mac,SPoC,CroW,GeM等)并用ROI Pooling,PCA 白化,L2-归一化等方式处理,一般最终维度为256,512,1024,或2048;用kNN,MR,DBA,QE,Diffusion等方式将得到的特征对数据库内的特征进行后处理获得最终特征;训练模型一般损失函数采用contrastive loss或triplet loss,最终比对一般采用余弦或欧式距离。
我们自主研发的算法主要做了以下优化:1. 对基础网络进行多层的特征提取(而不局限于全连接的前一层)并融合,降维等。2. 采用CroW算法的核心思想对特征图的不同空间点以及channel增加权重,不同于CroW算法,我们的权重是通过端到端方式学习所获得。在2018、2019年Google地标识别挑战赛中,极链科技AI研究院蝉联了两届全球冠军。
下面,介绍一下视频检索,也就是以图搜视频的流程。以图搜视频可以分为两部分,一部分是通过视频深度图像检索构建视频数据库,另一部分是用户检索时,输入图像到第一部分的视频库中进行检索。
具体来看,首先通过视频下载、视频数据库检索、特征提取、特征排序等生成一个特征表述数据库,当用户需求输入后进行特征提取、比对、排序和结构展示。这是标准的检索流程。在算法结构方面,用户输入后会经过卷积神经网络和索引得出粗检索结果,再通过细检索进行排序、查询,最后输出镜头信息,另外也可以通过剧目信息进行子部检索减少搜索任务的压力,同时提高算法的准确率。
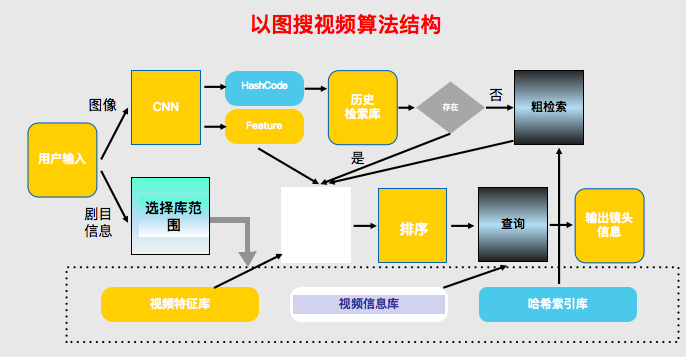
以图搜视频的核心在于我们自研的深度图像检索模型VDIR,由视频任务调度系统派发的视频分片,经过镜头检测分割成片段,片段信息经过VDIR会生成视频信息库、视频特征库以及哈希索引库。用户输入一张或者多张图像,同时可以指定剧目信息,比如古装剧、玄幻剧等,输入的图像经过VDIR算法提取到哈希编码和特征,首先会去历史检索库中查找是否有相似的检索,如果有直接使用特征即进行细匹配,没有就会先通过哈希编码到哈希索引库中检索,然后进行细匹配,根据匹配相似度进行排序后,从视频信息库中查询到视频片段信息,配合截图输出到界面。
深度图像检索模型VDIR会输出两部分内容,分别是用于快速检索的哈希编码以及用来细匹配的特征,一个片段的几个帧特征或者相邻片段的帧特征并不是都需要,因为我们设计关键帧筛选逻辑,只保留关键帧特征。
为了将以上算法实际落地,还需要进行工程化的工作。在工程化工作中,需要解决以下几个问题:1、算法进行并行化加速其运营;2、面对高并发状态解决分布式系统和多任务调度的问题;3、对资源调度进行算法分割与CPU+GPU配比;4、对高优先级任务规划处理策略。
最后,向大家介绍一下三个算法实际产业化应用的案例。
VideoAI视频智能识别和大数据运营系统,实现视频输入、识别、结构化数据管理和多维度检索全流程技术。极链科技独创独创全序列采样识别,对视频内的场景、物体、人脸、品牌、表情、动作、地标、事件8大维度进行数据结构化,32轨迹流同时追踪,通过复合推荐算法将内容元素信息升级为情景信息,直接赋能各种视联网商业化场景。
灵悦AI广告平台,通过VideoAI将全网海量视频进行结构化分析,对消费场景标签化,结合品牌投放需求,提供智能化投放策略和批量化投放,让用户在观看视频时有效获取相关品牌信息及购买,实现广告主精准投放的营销目的和效果。目前通过VideoAI技术的赋能,灵悦AI广告平台已完成2012年至今全网热门视频,实现扫描累计时长达15,600,000+分钟剧目复合双向匹配。开发了965类成熟商业化可投放情景,服务300+百家一线品牌,并与全网头部流量视频平台签订深度投放合作,实现广告创新营销的新动能。
神眼系统,广电级内容安全多模AI审核系统,可实现本地部署的高可用技术解决方案,提供长视频、直播、短视频的敏感、政治、色情、暴恐审核服务。产品核心功能包括:智能鉴黄(识别视频和图片中的色情、裸露、性感等画面);智能鉴暴(识别视频和图片中的血腥、暴力、枪支等画面);政治敏感人物识别(基于政治人物库,识别视频和图片中的国家领导人物或者落马官员等);涉毒/涉政明星识别(基于明星库,结合黑名单,识别视频和图片中的涉毒、涉政等明星)。
最后,想和大家强调一下数据对于人工智能发展的重要性。目前半监督、无监督算法还处于研究阶段,性能差距较大,我们所用AI算法大多基于监督学习,因此数据的体量和质量非常重要。我们要学会思考更多问题,例如采集数据与实际应用间的相关度,常规数据操作有哪些,如何获取“高效”的数据,如何应用数据管理工具让我们更好的管理、应用数据等等。谢谢大家!

评论 {{userinfo.comments}}
{{child.content}}

 {{money}}元
{{money}}元




{{question.question}}
提交







































